本文提出一种无标记的低成本表情动捕方案,仅基于低分辨率的单目网络摄像头实现中高质量的表情动捕
MEPS: Markless facial tracking and expression projection using single RGB WebCam
随着图形技术的成熟,表情动捕方法越来越多,但高精度设备动辄几个W的价格让个人创作者和小型开发团队望而却步。而且这些设备往往重量可观,非专业动捕演员戴在头上可能就只剩下“痛苦”的表情。有些动捕方案还需要在脸上画上标记点,使用十分不便。因此本文提出一种无标记的低成本表情动捕方案,仅基于低分辨率的单目网络摄像头实现中高质量的表情动捕。
Part A – Brief History of Markless Facial Tracking
先来看看专业的面捕设备长什么样,下图是《最终幻想:王者之剑》CG电影表情动捕现场。专业设备虽然能够实现质量极高的表情捕捉,但这比头还大的设备是不是看上去就很费劲。

于是各种轻量化的设备开始出现,同时都在朝着去掉脸上标记点的方向努力,但此时依然没有摆脱头戴式设备的局限。

直到2012年faceshift studio横空出世,彻底改变了现状,这是一套真正没有沉重头戴式设备、无标记、使用方便且动捕质量达标的解决方案。
Faceshift到底用了什么黑魔法?faceshift面捕方案的核心是借助深度相机实现用户的表情输入,也正是得益于微软Kinect等一众消费级深度相机的推出,使用faceshift,意味着你可以仅依靠下图中任意一款深度相机设备实现表情动捕。


GDC2015上,faceshift studio展示了他们强大的无标记面捕解决方案,不论写实风还是卡通风,甚至是从人到动物,faceshift都能轻松驾驭。


到这里,可能有同学觉得问题已经解决了,因为现在深度相机的价格不算昂贵,比如kinect的市场价在千元左右,个人开发者也能够接受。但不要忘了除了深度相机,你还需要一个faceshift studio才能开始你的表演。而faceshift studio的授权价格为一年1500美元。
时间继续往前走,2015年,突然CG界一个惊人的消息传出,震惊了手机界:Apple收购了faceshift,没错,就是做出你拿在手上的那个iPhone的Apple。

于是faceshift的技术被整合到iPhone,有了后来大家所熟知的Animoji功能。但如果iPhone的面捕就仅仅是Animoji这么简单,这里就不会提到iPhone了。Apple的野心显然不止于此,因为iPhone的ARKit动捕数据是可以导出的!比如说可以像下图中一样,将动捕数据导出到Unity3D,直接驱动三维角色的表情动画。

更绝的还不止于此,Apple打得一手推销iPhone的好牌:在iPhone中做面捕和导出动捕数据是不需要经过faceshift studio的,这相比于购买一台depth camera + faceshift studio license的价格显然是要低得多,以至于后来在国产独立游戏《光明记忆:无限》中,作者直接使用iPhone作为主角舒雅的面捕设备。

但显然iPhone的价格对于本文作者来说还是有点高(狗头。要是能有这样一套方案:直接基于价格低廉随处可见的网络摄像头进行动捕,岂不完美?
2017年实时三维动画软件iClone 7发布,其集成的混合式表情动捕方案Faceware能够实现基于网络摄像头及语音输入的无标记动捕,结合iClone自身强大的虚拟人创建能力,一套工作流直接打通了三维角色动画的“任督二脉”,提供了从捏人到绑定再到动画捕捉的全自动一站式流程,实力可谓非常恐怖。
但问题同样还是出在钱包上,iClone单独的授权费就高达199刀,faceware的授权还是独立的,不仅如此,许多其他模块也是拆卖模式,买下一整套完整的面捕动捕方案,需要990刀。
贫穷使我们相遇,看了看自己的钱包,我决定自己做一个。
The point is how to cut costs!
Part B – Implementing a Simple Markless Facial Tracker
**前置理论知识:**阅读接下来的内容之前,你可能需要先了解一些机器学习中人脸关键点检测(Facial feature point detection)、计算机视觉中三维重构理论(3D Reconstruction)、计算机网络中套接字(Socket)以及计算机图形学中三维骨骼动画及绑定的基本原理(Binding & Animation)的相关知识,本文不会对这部分原理作详细论述。
**DCC软件与编程语言需求:**阅读接下来的内容之前,你可能需要先了解WebGL、JavaScript、3dsMax、MaxScript以及.Net(C#)的基本使用。
这一节我们来实现整个面捕工具的第一个部分——面部关键点捕捉工具(Tracker)。如下图所示是我们将要实现的完整面捕系统流程,下文我们将这个系统简称为MEPS(Markless facial tracking and Expression Projecting System),Tracker是整个系统从接收网络摄像头的视频流输入开始所要经过的第一个模块。
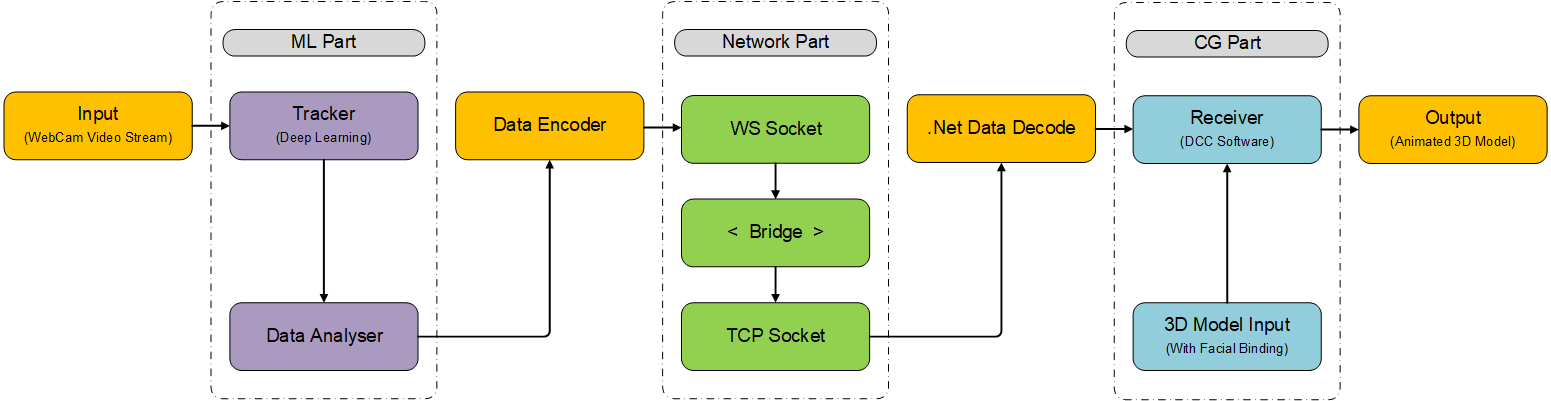
这部分我们使用JavaScript基于WebGL实现,选择WebGL是因为其运行、部署都十分方便,只需要一个浏览器就可以运行我们的Tracker,即使更换了设备,也可以通过部署在服务器上的版本快速构建工作流,不需要像OpenGL或OpenCV等进行复杂的环境配置;同时,在浏览器端调用网络摄像头获取视频流也是非常简便的。
人脸关键点检测方法中具有里程碑式意义的有如下五种:
(1)1995年,Cootes提出的ASM(Active Shape Model);
(2)1998年,还是Cootes提出的AAM(Active Appearance Model);
(3)2006年,Ristinacce提出的CLM(Constrained Local Model)算法;
(4)2010年,Rollar提出的cascaded Regression算法。
(5)2013年,Sun首次将CNN应用到人脸关键点检测,开创Deep Learning人脸关键点检测先河。
自2013年Sun等人在人脸关键点检测任务中使用CNN获得良好效果以来,众多学者将目光从传统方法转移到基于Deep Learning的方案,新方案不断被提出,不断突破检测精度的上限,例如从DCNN到Face++、从TCDCN到MTCNN等。
本文采用的是CVPR 2014上Vahid Kazemi提出的ERT(Ensemble of Regression Trees)算法[1],该算法主要解决单幅图像的人脸对齐(Face Alignment)问题,通过建立一个级联的残差回归树(GBDT)从图像的像素灰度值稀疏子集中估计人脸关键点(landmarks)的位置。
训练过程中可以给网络喂一些公有数据库里的标注数据,比如CMU Multi-PIE人脸数据库、MUCT数据库、300-W(300 Faces in-the-Wild Challenge)混合数据库等。本文选用的全部是68个标记点的数据,因此训练完成后输出也是68个landmarks。当然也可以添加一些手动标注的自己的照片,这样在自己使用的时候捕捉精度会有所提升。这个Trick在ZJU CAD&CG Lab一篇2014年的Paper: Real-time facial animation on mobile devices[2]中有所提及,在使用他们的移动端表情捕捉系统之前,他们会先为每个使用者拍摄60张手动标注数据的不同表情照片作为补充数据参与训练提高landmarks的对齐精度。

注意如果要在浏览器中调用网络摄像头获取实时视频流是需要将相关js脚本先部署到服务器上的,没有服务器也不要紧,这里可以通过nodejs、tomcat等快速搭建一个本地服务器,比如通过nodejs的http-server就可以,启动服务器后浏览器输入localhost:8080/your tracker name.html即可,非常简单。
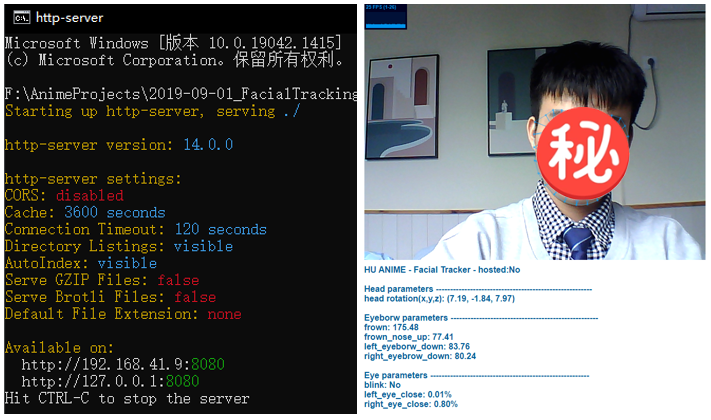
现在我们得到了一组68个landmarks,接下来如何基于这些信息将表情投射到我们的虚拟人脸上呢?这些landmarks是不能直接使用的,因为landmark的坐标是2D的,为了实现表情映射,我们有两条路可以选:
1、 继续沿着ML的路子走到黑,根据捕捉到的landmarks数据,分析出视频当前帧里演员的情绪(Facial Expression Recognition),例如喜、怒、哀、乐的百分比,得到多个范围为0-100的情绪状态数据,然后直接映射到我们目标三维角色的Blend Shape Target通道值上去;方法有很多,比如完全基于landmarks的方案和融合了Image与Landmarks的方法,具体方法的选择可以参考Shan L 等人的Deep Facial Expression Recognition: A Survey [4]这篇综述;
2、 借助计算机视觉中的三维重构方法,对landmarks的坐标做摄影机求反得到其在真实场景下的三维坐标,再结合我们之前文章中提出的表情重定向方法,将landmarks上携带的动画信息重定向到目标三维角色的骨骼上得到表情动画输出。
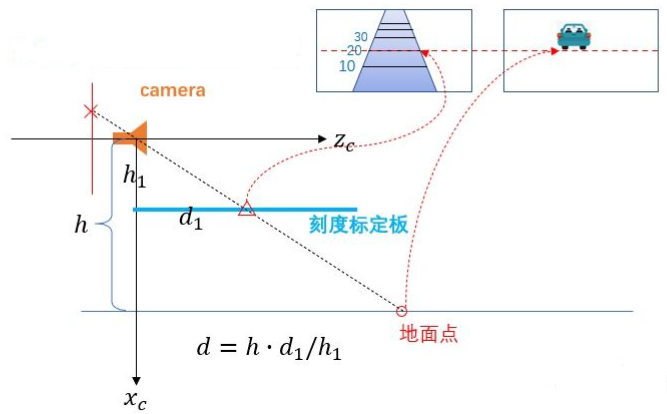
但实际实现中由于我们仅使用一个分辨率为640P的网络摄像头,精度非常有限,为了提高表情捕捉的准确性,MEPS在实际实现中采用的是混合方案。三维重构部分,通常计算机视觉中会采用双目摄像头方案,这样能够得到精确的求反结果;而如果仅用单目RGB相机,由于信息缺失太多,像素点的深度值是无法直接求解的。
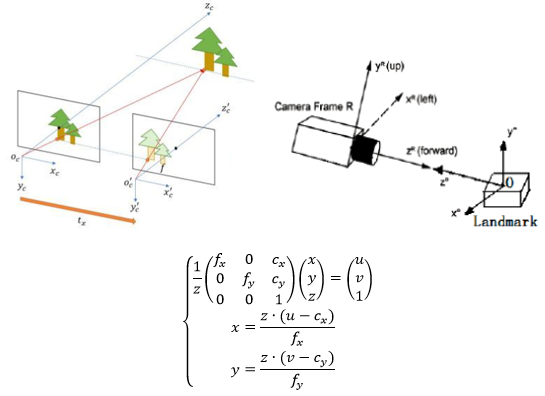
上式为单目针孔相机模型,其中u和v是视频流中时刻t下单帧图像中任意像素点P的屏幕空间二位坐标;(x, y, z)是该像素点在摄影机空间下的三维坐标,其中z为深度值。众所周知当仅给定一组坐标(u, v)的时候,我们是无法直接求解得到z值的。
但如果存在这么一种情况:摄像机的视角和距离地面的高度都是固定的,那么我们就能事先得到摄影机空间下地面的坐标,于是就可以在上面的相机模型中新增一条约束条件:
其中A、B、C、D都是已知常数,于是我们就可以求解得到深度z了。这是在自动驾驶模拟中应用十分广泛的一种求解方法。在我们的MEPS系统中,摄像头的离地高度同样是不便的,演员面对屏幕,面部离地高度也是几乎不变的,因此我们就可以利用相似三角形原理对landmarks的坐标进行求反。
那么如果既存在演员运动,摄影机也要运动的情况,怎么办呢?这种情况下要硬要求反也不是不可以,我们可以简单通过选取几个关键的landmarks,譬如通过两个眉尾的连线以及额头和鼻尖的连线,来非常rough地估计一个头部的相对旋转角度。下方是这个trick的伪代码描述:
function FaceAngleEstimation(landmarks, imgDims) {
const angle = (0, 0, 0);
const radians = (a1, a2, b1, b2) => Math.atan2(b2 - a2, b1 - a1);
if (!landmarks || landmarks.length !== 68) return angle;
// roll is face lean left/right
// comparing x,y of outside corners of leftEye and rightEye
angle.roll = radians(landmarks[36].x, landmarks[36].y, landmarks[45].x, landmarks[45].y);
// yaw is face turn left/right
// comparing x distance of bottom of nose to left and right edge of face
angle.pitch = radians(
landmarks[30].x - landmarks[0].x, landmarks[27].y - landmarks[0].y,
landmarks[16].x - landmarks[30].x, landmarks[27].y - landmarks[16].y
);
// pitch is face move up/down
// comparing size of the box around the face with top and bottom of detected landmarks
const bottom = landmarks.reduce((prev, cur) => (prev < cur.y ? prev : cur.y), +INF);
const top = landmarks.reduce((prev, cur) => (prev > cur.y ? prev : cur.y), -INF);
angle.yaw = 10 * (imgDims.height / (top - bottom) / 1.45 - 1);
return angle;
}这种方法求解得到的三维landmarks坐标并不会特别精确,但用在大范围运动的数值上比如上述头部的旋转角度的求解上,精度是完全足够的。再比如眼睛部位的眨眼判断,我们也完全可以不去求解其三维坐标。基于文献[5]中Soukupová 和Čech的相关研究我们可以得知,人眼在开合过程中左右眼角和上下眼皮的距离比值曲线会在眼睛闭合时产生一个明显的波谷,如下图:
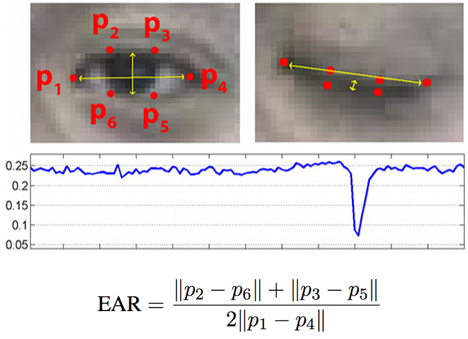
于是我们就可以利用这一特性,简单地基于上式求解眼睛的闭合百分比,不仅计算量小,精度也能够达标。
除了landmarks的三维坐标重构,MEPS在处理动捕数据时还会综合考虑表情整体的情感表达,这部分输出的是一系列情感表现的百分比,范围为0-100。例如,我们可以简单地通过分析嘴角连线长度以及眼角连线长度之间的关系来得到当前演员表情的情绪状态是否是微笑,伪代码如下。
// Smile Detection
setPoint(face.vertices, 48, p0); // mouth corner left
setPoint(face.vertices, 54, p1); // mouth corner right
var mouthWidth = calcDistance(p0, p1);
setPoint(face.vertices, 39, p1); // left eye inner corner
setPoint(face.vertices, 42, p0); // right eye outer corner
var eyeDist = calcDistance(p0, p1);
var smileFactor = mouthWidth / eyeDist;
// 1.4 - neutral, 1.7 - smiling
smileFactor = clamp(smileFactor -1.4, 0, 1) / 0.3; 至此我们就完成了Tracker模块的开发以及landmarks动捕数据的分析流程。
Part C – Implementing Dataflow and Socket Bridge
紧接着我们来完成数据流模块,这个部分的主要流程包括:
1、 对Part B中已经完成分析的动捕数据输出进行编码;
2、 实现一组一对多的Local Facial Tracking Data Server/Client,WebGL(JavaScript)端host一个server,不断广播编码后的动捕数据;
3、 任意DCC软件或游戏引擎(下文我们以3dsMax为例)作为client,不断接收动捕数据并解码;
这里我们选用3dsMax作为接收端例子是因为在max中实现实时动捕相比在Unity等引擎中要更加困难,比如MaxScript并不支持WS Socket,以及不支持多线程等,这些都是需要克服的困难。
Part B中的动捕数据我们直接在Data Analyser模块中进行编码。Json和XML等格式放在这里显得体量有些太大了,由于是实时动捕应用,我们需要一个更轻量的数据存储格式来提升数据传输和编解码的速度。因此我们自订了MEPS中传输动捕数据使用的数据传输协议,这个协议的结构非常简单,如下所示:
[头部根骨骼朝向] , [18个3D landmarks坐标] , [50个2D landmarks坐标] , [12个情绪通道数据] , [其他可扩展数据] |
所有数据之间以符号’,’分隔,’|’为一帧数据的结束标记。完成编码后向我们的WS Server发送一条字符串消息即可:
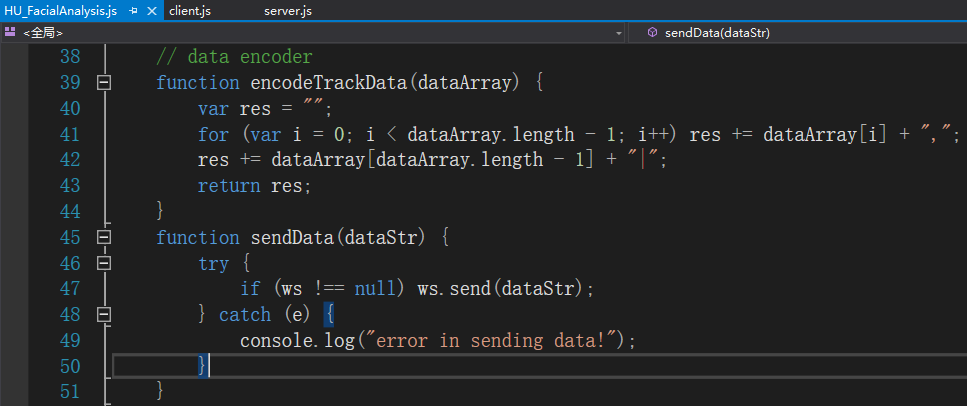
Server的实现比较常规,没什么好细说的。红框里是数据接收的部分,从Analyser模块每帧接收一次数据后再全局广播出去,这样就可以做到一次对接所有我们期望接收到动画的软件。Server我们同样用nodejs来host,注意端口号不要与之前Tracker的重合。
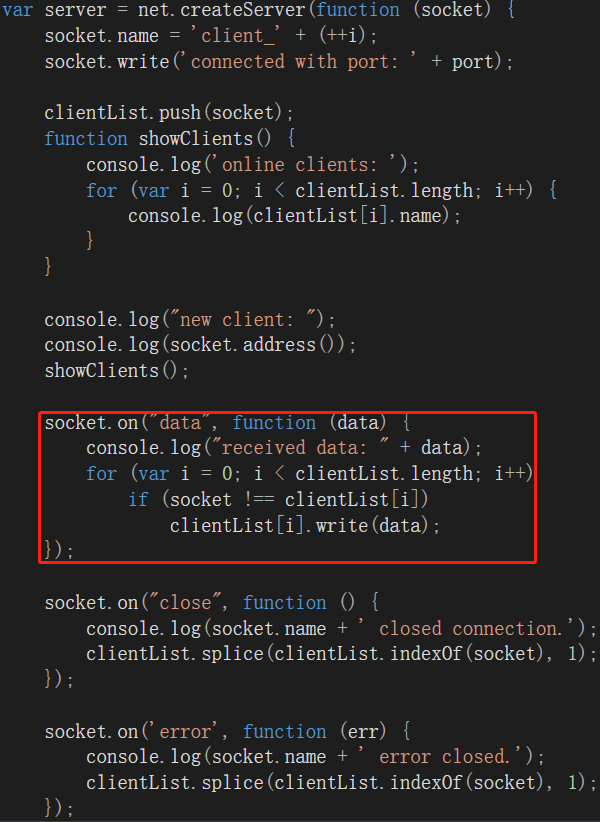
需要注意的是由于我们接下来需要基于MaxScript实现client,而MaxScript是不支持WS Socket的,其仅支持TCP Socket,因此我们还需要实现一个Bridge,实现从WS Socket到TCP Socket的消息转发。
这部分我们就不去自己做实现了,还是基于nodejs搭一个从WS Socket到TCP Socket的转发代理,两行代码就能解决问题,同样需要注意端口号不要重复:
//安装
npm install -g ws-to-tcp
//启动 from websocket端口 to TCP端口
ws-to-tcp --from 8000 --to 9000
至此我们就完成了数据流模块,现在不论是支持WS Socket还是TCP Socket的client都能够顺利接收到我们的面捕数据了(注意区分端口,不同类型的client要分别从两个端口接收数据)。
Part D –Facial Animation Retargeting in 3dsMax
这一节我们实现3dsMax端的Reciver模块。MaxScript中我们首先需要解决的一大难题是:MaxScript不支持多线程,也就是说当MaxScript在解析Server发来的数据时,Max的主视图就会卡住,无法实现实时将表情动捕数据应用到角色模型上。
但从MaxScript开始支持与.Net交互后,事情出现了转机。.Net中有一个BackgroundWorker控件,在System.ComponentModel命名空间下,BackgroundWorker提供了执行异步操作(后台线程)的功能,它允许用户在一个单独的线程上执行多线程任务。当我们需要执行诸如下载等耗时任务时,又需要同时相应用户界面操作,此时就可以使用BackgroundWorker。
MaxScript中调用BackgroundWorker的流程和.Net中直接调用是相似的,只不过多了一些封装,我们需要先创建一个DotNetObject对象,然后添加EventHandler:
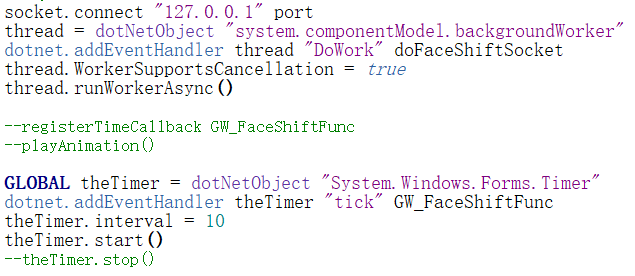
让BackgroundWorker不断在后台线程中调用我们的解码器,然后将解码后的数据传递到虚拟角色上即可。这里我们可以额外定义一个Timer,用来控制调用解码器的频率。因为网络摄像头捕捉到的视频流的帧率是有限的,比如本文使用的640p网络摄像头捕捉到的视频流帧率在24-30fps左右,这和Max的视口刷新率是对不上的,如果频繁调用解码器,那么多数帧里解码器都是空调用的状态,无意义地浪费了性能,因此可以通过设置.Net 的Timer.interval来匹配client和server的帧率。
解码器的实现非常简单,使用正则表达式按照符号’,’划分数据即可。需要注意的是TCP Socket协议只管无脑发送数据,不关心每一帧数据的完整性,会产生**“半包”**和“**粘包”**问题,这与改进版的WS Socket不同。因此发送端我们不需要关心任何数据完整性问题,但接收端我们就必须手动维护一个数据池(Data Pool),每帧接收到的数据先手动判断一下结尾字符是不是’|’,如果不是,代表这一帧数据没有来得及发完,需要等待下一帧到来,拼接数据后再进行下一步操作;此外,即使结尾字符已经是’|’,我们也要过一遍这一个包里发来的数据,因为还可能存在“粘包”问题,也就是一帧或多帧的数据被压在了一个包里发送过来。如果在包体数据的中间发现了结束字符’|’,我们就需要手动做不同帧数据的切分。
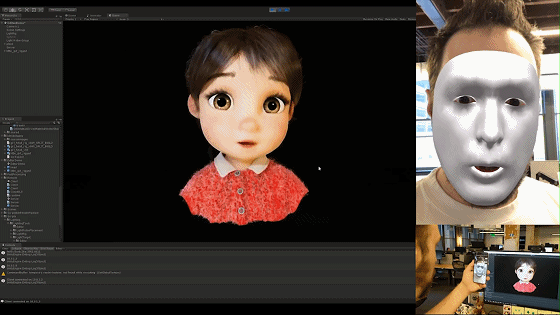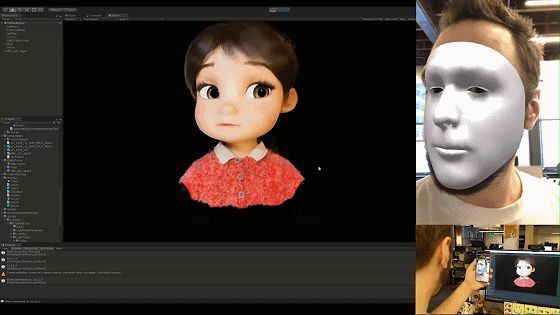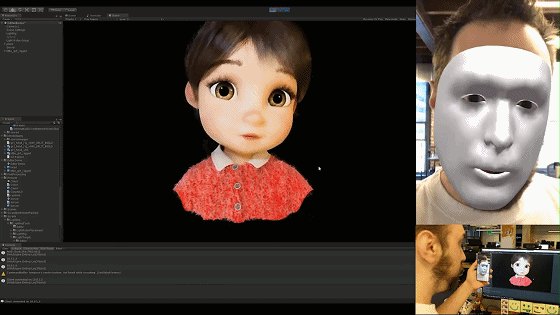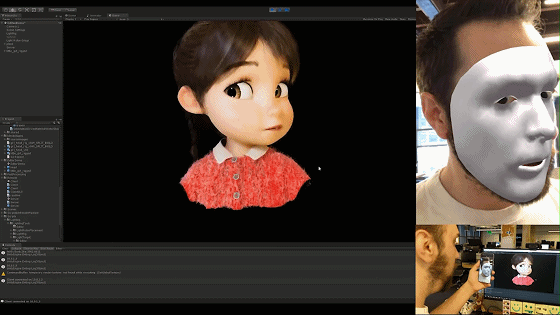
解码完的数据直接应用到blend shape的通道值上或者直接基于我们之前文章中所述的表情重定向方法将其重定向到角色面部骨骼上即可。来看看现在的面捕表情捕捉效果吧:
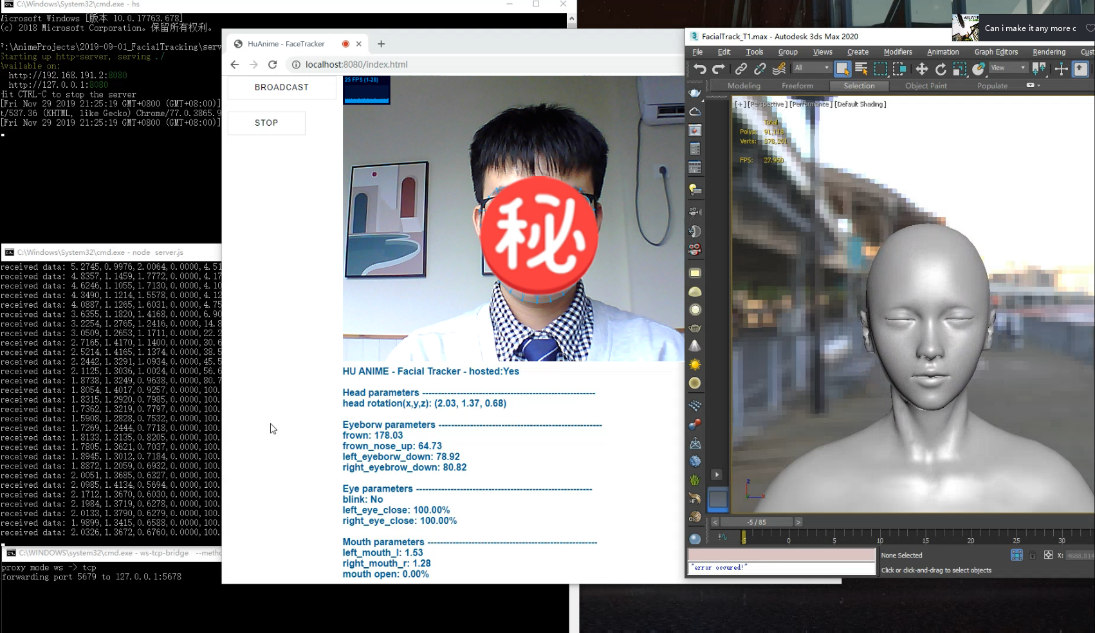
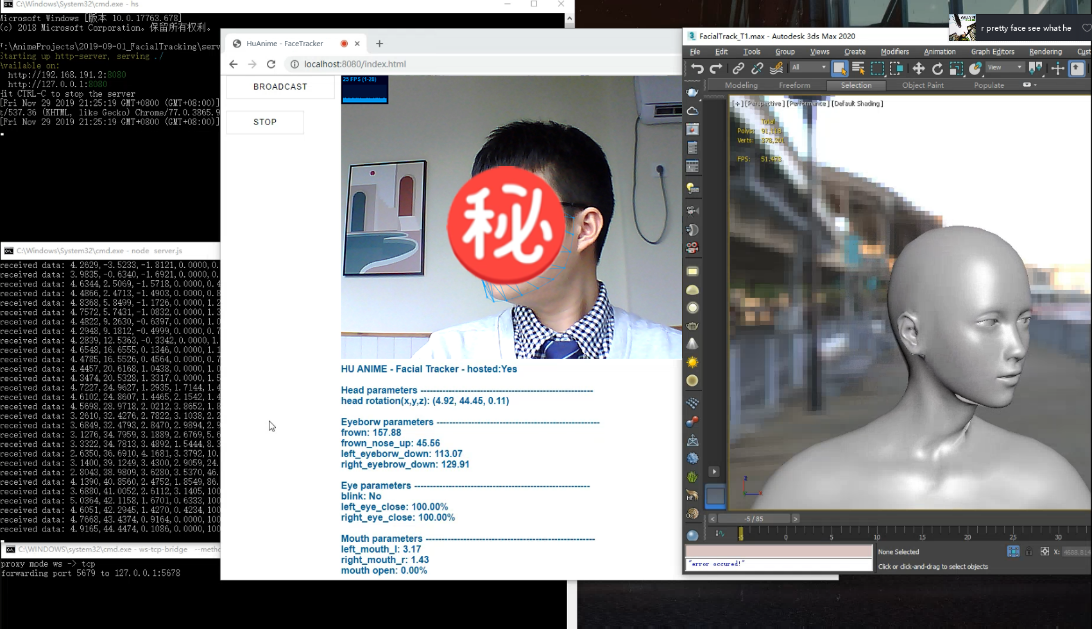
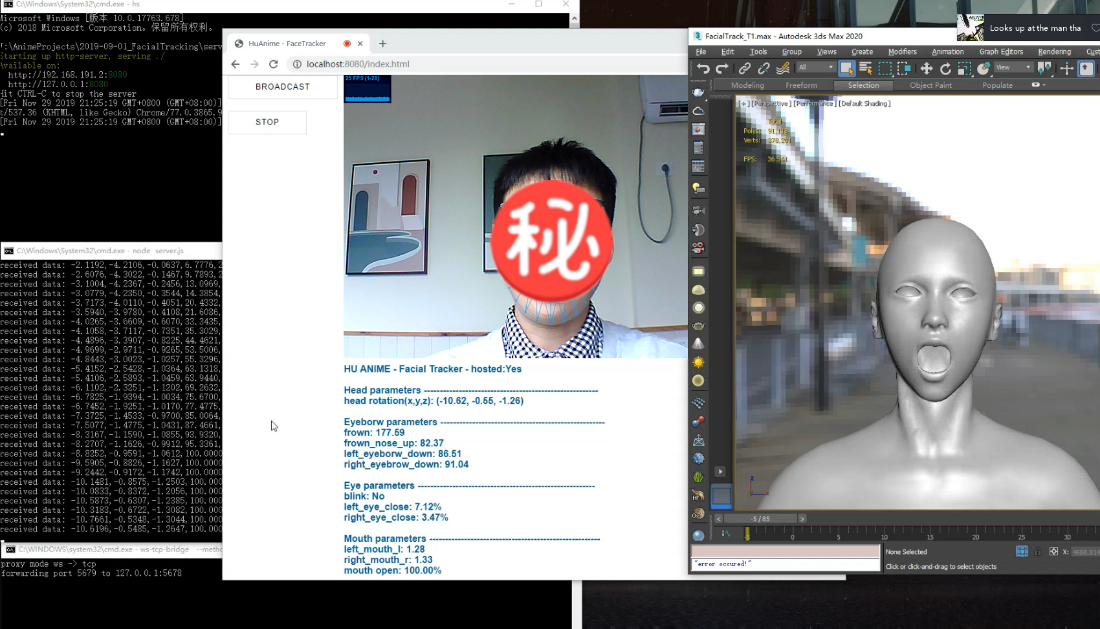
至此我们已经基本完成了MEPS的整套动捕流程,但现在直接使用MEPS做动捕时我们会发现两个问题:
1、 面部关键点的移动会产生抖动,效果不好;
2、 由于基于视频关键点的面部表情捕捉信息有限,不像基于深度相机做捕捉可以精确重建面部mesh,从而将表情动作过程中产生的面部皱纹也重定向到虚拟角色上,这就导致我们的虚拟角色生成的表情动画缺乏微表情细节,情感表达比较生硬。
下一节我们就来探讨如何进一步改善这些问题,让MEPS的面捕效果达到可用的产品级。