直接使用前文中完成的MEPS版本进行动捕,我们会发现输出动画的抖动十分严重且缺乏细节。本篇我们基于多源数据增强MEPS的动捕细节表现及稳定性。
MEPS: Markless facial tracking and expression projection using single RGB WebCam
Part E – Detail Enhancement & Time Spatial Optimizations
E-1 时空表情动画平滑 / Time Spatial Facial Animation Filter
直接使用上一节中完成的MEPS版本进行动捕,我们会发现输出动画的抖动十分严重,尤其是眼睛部位。造成抖动的因素有很多,比如直接使用2D landmarks坐标点计算眼睛的闭合百分比、摄像头的分辨率不足等。

除了提高摄像头设备的分辨率、将Landmarks坐标转换为3D再进行计算之外,我们还可以通过时空间平滑进一步改善动捕动画的质量。
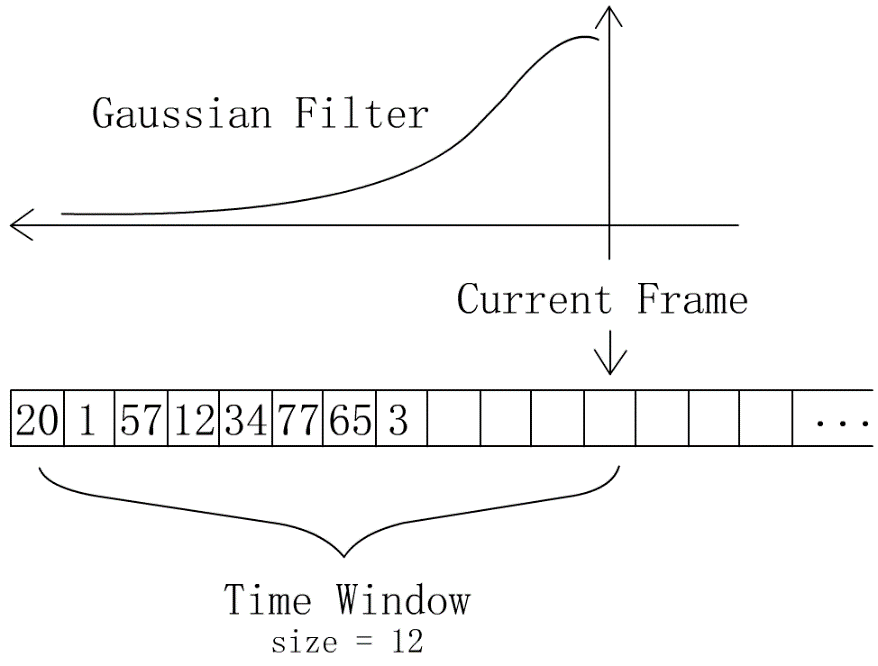
就像光栅化渲染管线中做TAA一样,我们可以在Receiver模块维护一个动态的滑动窗口,对动捕数据做一个时空间序列上的高斯滤波。MEPS的实际实现中使用一个大小为12的窗口,执行平滑操作时取左边一半的2D高斯核进行计算。
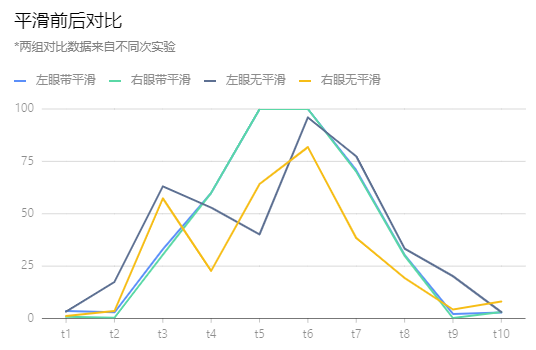
下图为执行时空间平滑前后的动捕数据对比,我们在一个完整的眨眼周期内按相同的时间间隔采样10次,分别记录左眼与右眼的闭合百分比。闭合百分比范围为0-100,0代表眼睛完全张开,100代表眼睛完全闭合。
从数据中可以看到平滑后的眨眼动画抖动问题得到了极大改善,同样的处理方法也可以沿用到嘴部等其他部位。

E-2 音频数据融合 / Audio based Facial Animation Enhancement
借鉴faceware中的处理方式,我们这里也可以通过增加音频信息的方式,帮助MEPS在捕捉演员的对话表演时得到更完美的口型动画。
我们可以简单地仅处理a,e,i,o,u几个元音音节,也可以根据中文发音的特性多补充一些连读音节得到更精细的动画效果。现成的音频分析库有很多,MEPS中使用的是Microsoft推出的SAPI语音引擎,SAPI可以转换人类的声音语音流到可读的文本字符串或者文件。SAPI的详细使用流程就不在这里赘述了,大家感兴趣可以自行到Microsoft官网去查阅手册。
最后我们通过“置信度”对从视频流中得到的动捕口型与从语音中得到的音节口型做混合,得到最终的口型动画输出。混合过程如下式:
其中LipAnim(t)为t时刻下的口型动画输出,vA为视频动捕口型动画曲线,aA为音频口型动画曲线;c为置信度,其主要考虑vA在t时刻下平整程度,如果平整度较低,说明此时视频动捕结果比较noisy,于是我们就在输出结果中更多地混合来自音频的动画曲线。
E-3 细节增强 / Facial Animation Detail Enhancement
MEPS的实现终于来到了最后一部分,last but not least,这部分细节增强的实现对最终输出的动画效果来说是至关重要的一部分。由于MEPS中使用的输入设备仅仅是没有深度信息的低分辨率单目RGB摄像头,所以学界现在比较流程的去重构3D Face Mesh[10-12, 16]得到皱纹纹理[13, 14]的流程是行不通的。通过单目RGB只能重构出非常粗糙且丢失了高频细节的面部网格,虽然可以直接基于RGB图像恢复面部法线,但质量是无法达到产品级需求的,更何况我们使用的还仅仅只是一个640P的摄像头。
MEPS中我们另辟蹊径,采用的表情细节增强方法来自于Beeler T等人于14年在TOG上提出的Facial Performance Enhancement Using Dynamic Shape Space Analysis [18]一文。这篇Paper中将面部面部动捕流程和面部动画细节分离,建立一个高频细节数据库,在演员表演动捕得到粗糙表情动画的基础上,叠加高频细节,还原动捕演员的表演细节例如人脸在动态过程中产生的细小皱纹、面部不同部位之间由于动态的碰撞挤压产生的堆积效应等。整个系统流程如下图所示。
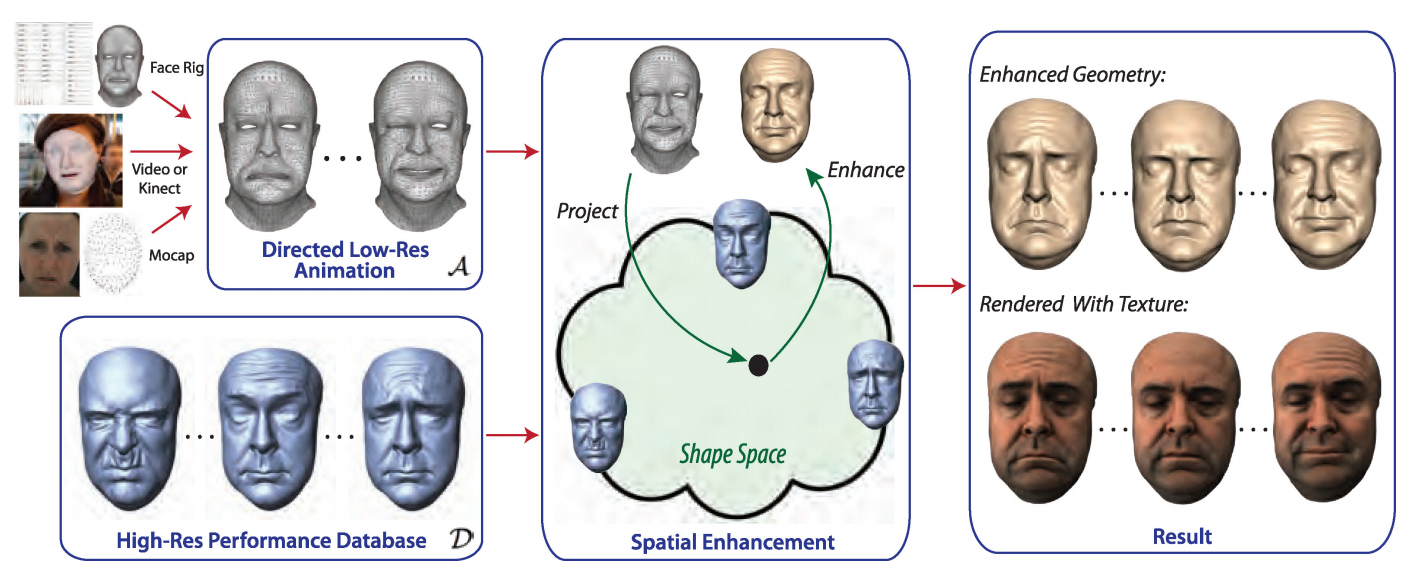
整个流程可以划分为四个大步骤:Pre-Processing、Performance data input、Shape spatial enhancement以及Time spatial enhancement。
Pre-Processing阶段基于多视角摄影机扫描演员面部得到高模,利用拉普拉斯平滑(Laplacian smoothing)算法分离高频细节,建立数据库。

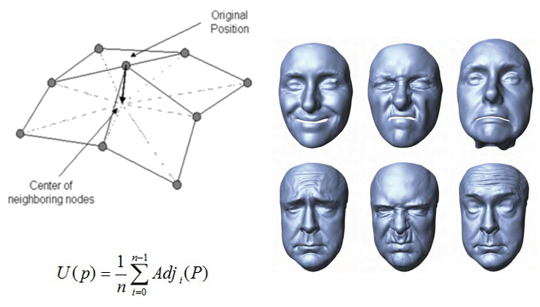
由于扫描得到的数据库中的细节向量顶点非常密集,逐一计算性能压力太大,于是接着Beeler T等人会对面部mesh的顶点进行分簇,以每一个簇作为独立向量对数据库中的特征向量进行压缩。
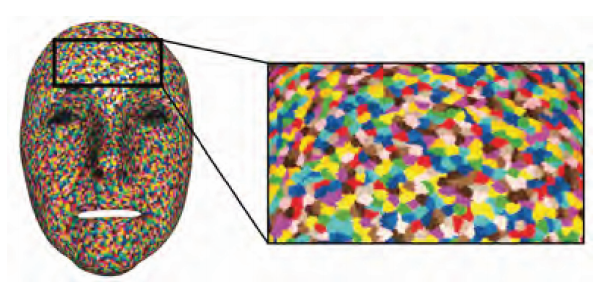
Performance data input阶段是常规的演员表演动捕阶段,得到一个毫无细节的动捕动画即可。重点是在Shape spatial enhancement阶段,我们要根据输入的动捕动画匹配数据库中的对应状态位置,然后将数据库中的静态表演细节映射到动捕动画上,得到高细节的表情动画输出。
数据库中高频细节的匹配是基于最小二乘法(Least-Square Method)对特征向量做匹配实现的:
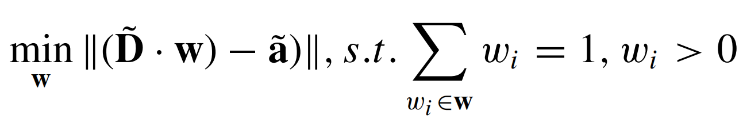
当然了,由于每一个时刻下单帧表情中同一张脸上的不同簇可能会映射到不同的数据库细节数据上,如下图中眉心和额头混合了两组不同的细节数据:

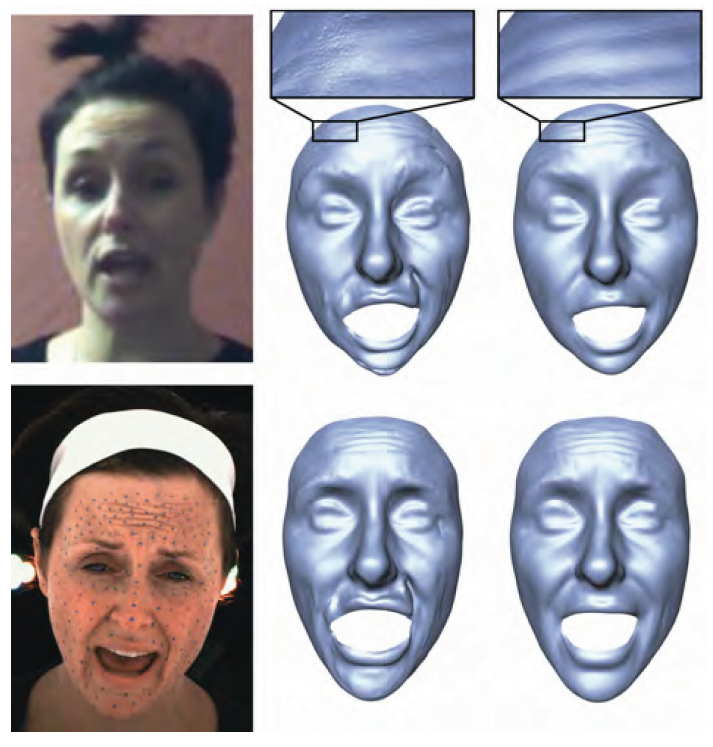
不同部位的高频数据直接叠加可能会出现接缝、不平整等一系列问题,于是Beeler T等人还会在输出最终的表情动画前对混合结果再做一次平滑处理。下图中间一列是直接混合高频细节的结果,可以看到嘴角部分十分明显的接缝;右侧一列是平滑后的混合结果。
MEPS中借鉴了这篇Paper中的Shape spatial enhancement部分,我们首先也建立一个高频细节数据库,数据库中手动制作常用表情的高频细节blend mesh,然后使用和论文中一样的方法,根据视频动捕输入,寻找对应的各个部分的细节,进行动态叠加与平滑,得到最终的高质量动画输出。

上图为MEPS测试中使用的角色模型绑定以及表情细节数据库,下图分别为细节增强前后的动捕动画输出以及增加纹理贴图之后的带表情动画角色渲染结果。


Conclusion
MEPS是我个人近期做的一次自我感觉较好的业余实践,从CG到网络、从ML到视觉、从Web端到DCC端,是一个综合性很强的课题,对自己来说各个方面都是一次挑战与检验。本文记录一下MEPS实现过程中的一些方法领悟,希望能给读到本文的小伙伴一些启示。
MEPS所需硬件成本极低,可扩展性强,能够快速接入各种DCC软件或游戏引擎,可以帮助小型工作室和个人开发者快速构建自己的表情动画工作流,提升开发效率,节约成本,并得到质量还算可以接受的表情动画。
硬件方面,我们全程只使用了一个分辨率仅640p的网络摄像头,成本不到30元。以一顿饭钱的超低价格完成了中高质量的产品级表情动捕。
最后感谢看到这里的小伙伴,祝你新年快乐!